Über Assoziationen lassen sich in Ruby on Rails verschiedene Modelle miteinander verbinden und so einfacher Daten abfragen, aktualisieren und einfügen. In diesem Artikel geht es um zwei Aspekte, die ich im Internet nur schwer recherchieren konnte:
- Assoziationen zwischen verschiedenen Datenbanken
- Dynamische Assoziationen (der Tabellenname des assoziierten Modells ist dynamisch und hängt von einem Attribut ab)
Anwendungsbeispiel
In meinem Fall geht es um das Modell Contact, welches in der Rails-Anwendung die Kontakte/Aufgaben eines Testmieters verwaltet. Pro Kontakt wird in LimeSurvey ein Teilnehmer eines Fragebogens hinterlegt, der den Fragebogen ausfüllen kann. Die eingegebenen Daten des Testmieters sollen in der Rails-Anwendung mit dem Kontakt (Contact) verbunden werden. Dabei gibt es diese Herausforderungen:
- Die Datenbank, in dem die Tabelle contacts liegt, ist ralv während die Fragebogen-Antworten in der Datenbank limesurvey liegen.
- Die Fragebogen-Eingaben liegen je nach Kontakt in verschiedenen Tabellen. Der Tabellenname ist z.B. lime_survey_661185, wobei 661185 die ID des Fragebogens in LimeSurvey ist. Die ID des Fragebogens wird im Kontakt gespeichert.
Die Struktur der Tabellen ist also:

wobei der Name der Tabelle lime_survey_* von contacts.fragebogen_id abhängt. Deutlicher wird dieser Aspekt in der Datenansicht:
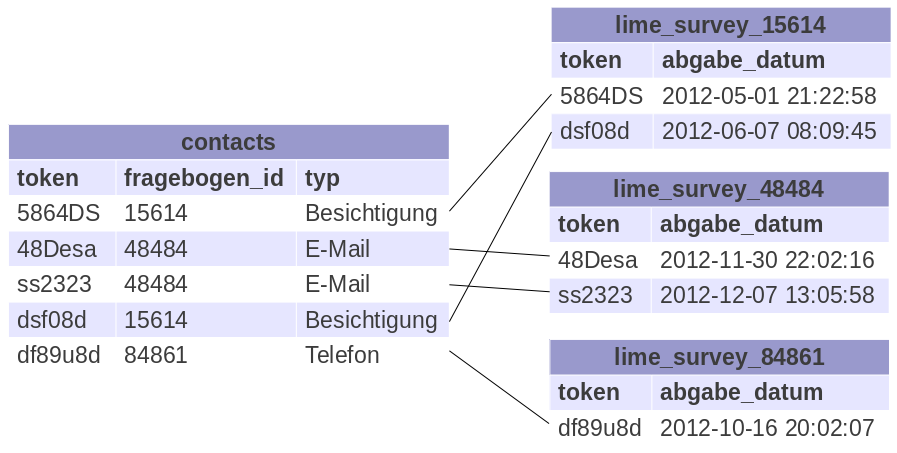
Assoziationen zwischen verschiedenen Datenbanken
Kümmern wir uns zunächst um diesen einfacheren Part: Modelle aus unterschiedlichen Datenbanken. Als Erstes muss eine zusätzliche Datenbank-Verbindung in /config/database.yml eingerichtet werden:
[code]limesurvey:
adapter: mysql2
encoding: utf8
username: [DBUSER]
password: [DBPASSWORD]
database: limesurvey[/code]
Für die Tabellen lime_survey_* wird zudem ein Modell namens LimesurveyData erstellt:
[code lang=“ruby“]class LimesurveyData < ActiveRecord::Base
establish_connection :limesurvey
self.table_name_prefix = ‚limesurvey.‘
self.table_name = ‚lime_survey_661185‘
has_one :contact, :primary_key => "token", :foreign_key => "token"
end[/code]
Betrachten wir den Quellcode zeilenweise:
1. Zeile: Die Klasse erbt von ActiveRecord, womit sie die Funktionen eines Rails-Modells erhält.
2. Zeile: Für die Klasse soll die vorher in /config/database.yml eingerichtete Datenbank-Verbindung verwendet werden.
3. Zeile: Um generell eine andere Datenbank in einer SQL-Abfrage zu spezifizieren, wird folgende Syntax verwendet Datenbank.Tabelle.Spalte. Rails 3.1 spezifiziert standardmäßig nicht die Datenbank in Abfragen, daher wird die Datenbank über den table_name_prefix in allen Abfragen des Modells eingefügt, sodass klar ist, welche Datenbank bei diesem Modell zu verwenden ist.
4. Zeile: Der Tabellenname wird normalerweise aus dem Klassennamen errechnet. In diesem Fall soll zunächst statisch die Tabelle lime_survey_661185 verwendet werden.
5. Zeile: Die Assoziation zu dem Modell Contact wird als 1:1-Beziehung eingerichtet. Dabei wird festgelegt, dass über das Attribut token in beiden Tabellen die Verbindung hergestellt wird.
In der Contact-Klasse wird zusätzlich ebenfalls die Assoziation zur LimesurveyData-Klasse eingerichtet:
[code lang=“ruby“]class Contact < ActiveRecord::Base
…
has_one :limesurvey_data, :class_name => "LimesurveyData", :primary_key => "token", :foreign_key => "token"
…
end[/code]
Der table_name_prefix muss in der Contact-Klasse nicht gesetzt werden, da standardmäßig die richtige Datenbank verwendet wird.
Dynamische Assoziationen
Um die dynamische Assoziation, also den richtigen LimesurveyData-Tabellennamen in Abhängigkeit zur Fragebogen-Id zu setzen, haben wir den wichtigsten Befehl bereits in der LimesurveyData-Klasse kennengelernt: self.table_name
Die Frage ist, an welcher Stelle der Tabellenname gesetzt werden muss. Der Tabellenname kann nicht in der LimesurveyData-Klasse definiert werden, weil dort unklar ist, welche Fragebogen-Id für die Assoziation relevant ist. Die Contact-Klasse ist der bessere Kandidat, denn schließlich wird dort die Fragebogen-Id gespeichert. Aber wie kann der Tabellenname eines anderen Modells gesetzt werden? So:
[code lang=“ruby“]class Contact < ActiveRecord::Base
…
after_initialize :setTablename
…
has_one :limesurvey_data, :class_name => "LimesurveyData", :primary_key => "token", :foreign_key => "token"
…
def setTablename
LimesurveyData.table_name = "lime_survey_#{self.fragebogen_id}"
end
…
end[/code]
Starten wir diesmal in mit der setTablename-Methode in den Zeilen 7-9: Sie setzt den Tabellenname der Ḱlasse LimesurveyData auf den dynamischen Namen.
In Zeile 3 wird diese Funktion als Callback-Funktion definiert, die immer dann ausgeführt wird, wenn die Contact-Klasse initialisiert wurde.
Und das ist alles: Wir können nun ganz einfach von einem Kontakt auf die korrekten Fragebogen-Antworten zugreifen, obwohl die Daten in einer anderen Datenbank liegen und über verschiedene Tabellen verteilt sind.

